Before we had our DAM in place, we were able to identify that some of the assets we acquired for our projects already had a fair amount of metadata embedded. This metadata was unreliable as it came in from disparate libraries, but we wanted to leverage what was already there for our own system.
I identified that our system needed to be able to see IPTC and VRA schemas in addition to the standard Dublin Core, but we wanted to leave those preserved as source information.
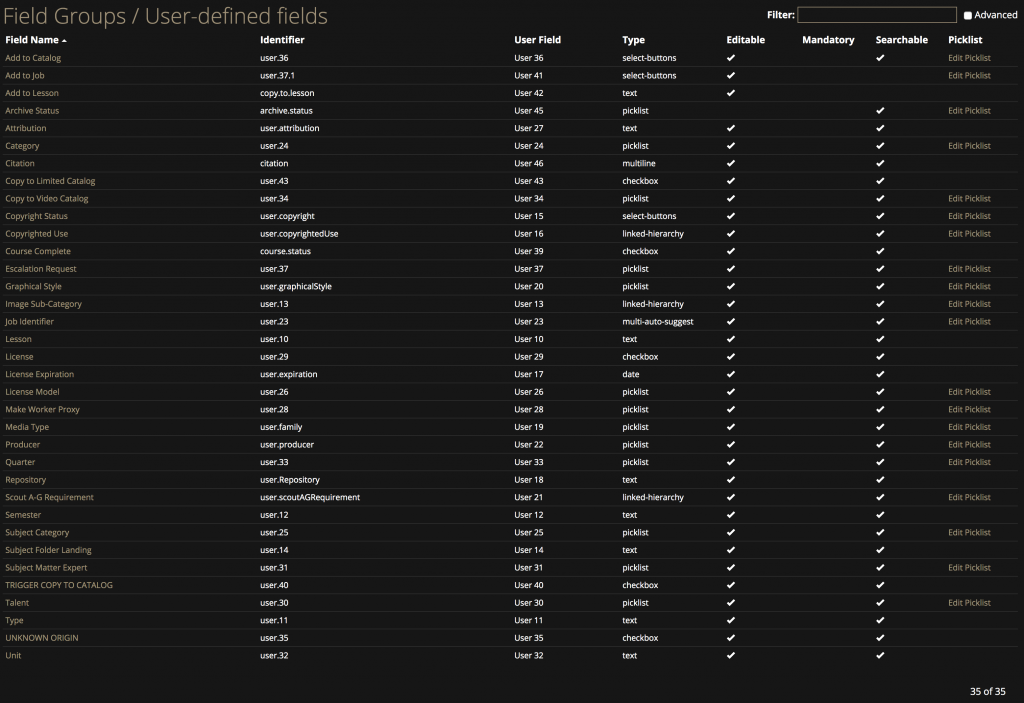
Our custom schema includes 35 administrative, structural, and descriptive fields that were created to facilitate the worker node scripting in addition to searchability and findability.
Metadata Dictionary
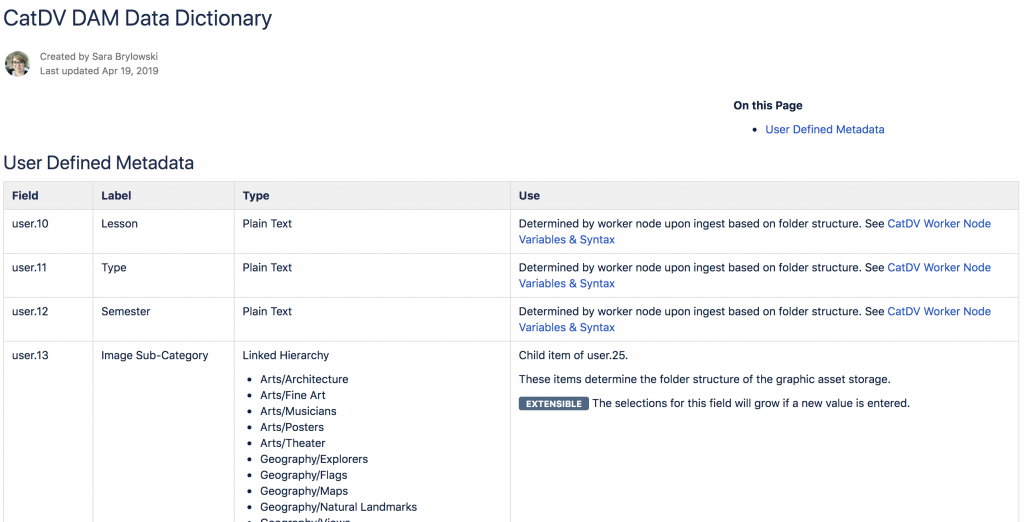
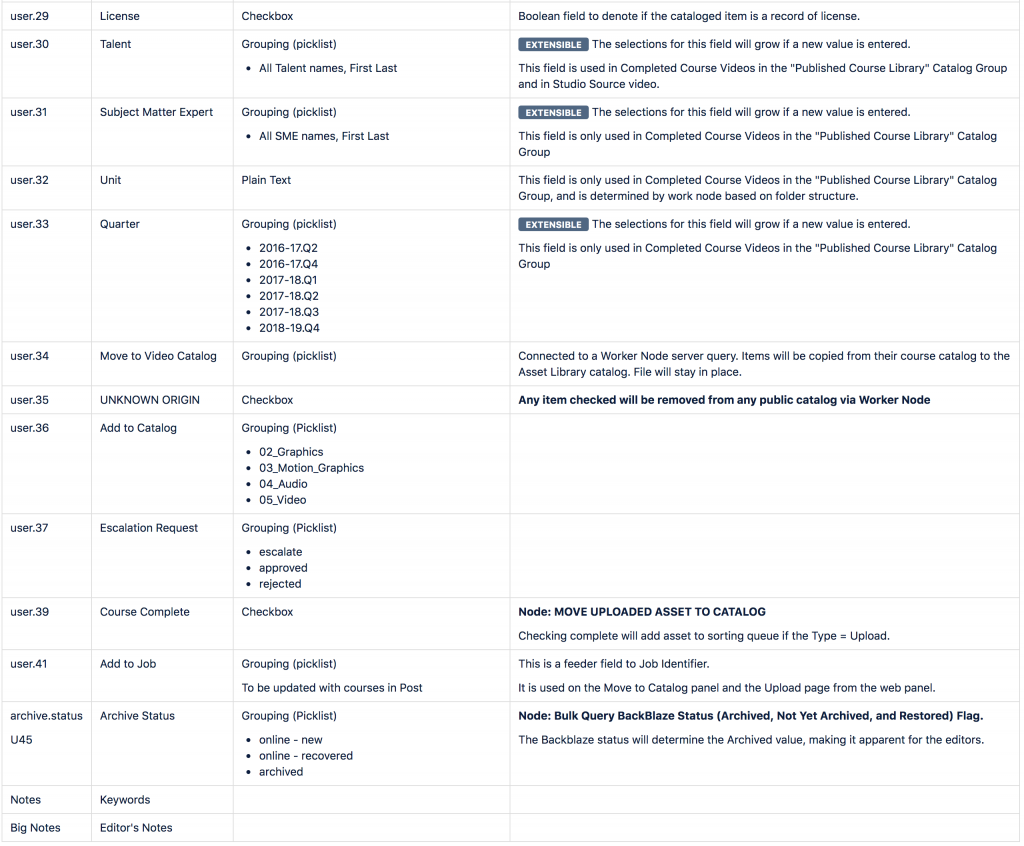
I created a Data Dictionary to inventory each of the fields in the custom schema that details the field label, field type, and how that field should be used. In the Field Type column, I also included the picklist information to review at a glance what might otherwise be difficult to access information.
In the Use field, I also added information on which Node scripts each field is used in so future managers have a complete picture of how the moving parts are connected.
The information about each field in the custom schema is documented in our Metadata Dictionary to aid understanding about the use of each field.
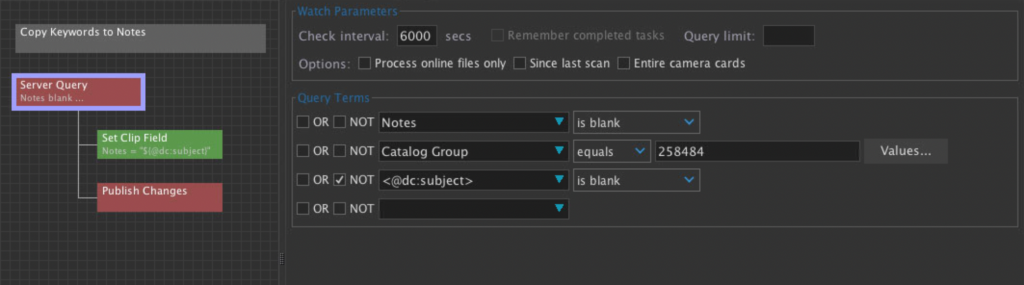
Worker Node Script
Metadata Preservation
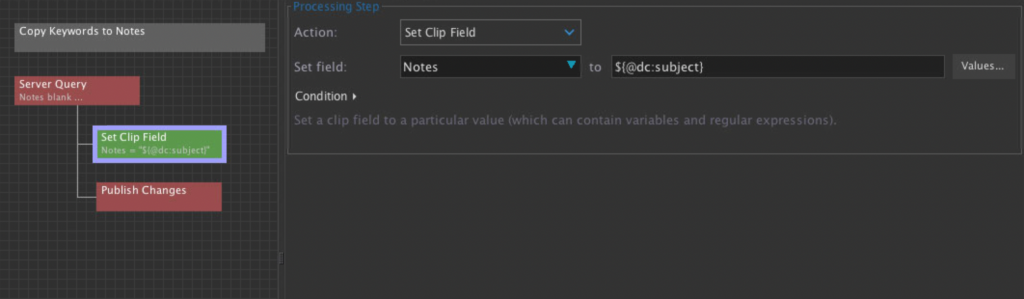
In order to preserve the legacy metadata, the worker node in our DAM actively hunts out assets that are cataloged with existing metadata in the dc:subject field, which we found was the most common location among disparate sources, and copies that into the keywords field in the local schema, allowing us to edit the information to suit our unique needs.